群晖入门到进阶系列(九):从磁盘空间损毁谈数据安全
说起这个事情已经是好几个月前的事了,目前 Alliot 的装备也是早在几个月前进行了一次升级。前面由于个人工作方面的转型,所以没有太多时间精力来就这件事情进行一次梳理,好在当时做了一些操作日志记录,恰逢今日公司团建,下班比较早,来写写那次 “群晖磁盘空间已损毁” 的事故,顺带从一个不那么成熟的运维工程师的角度,谈谈存储安全与备份策略。
事故背景
由于 Alliot 自己本身在一开始对群晖这个系统也是处于非常陌生的程度,对 不到300块捡一台4盘位NAS——蜗牛星际上车记 这套硬件也是当玩具的心态,没打算玩长久。所以这套 NAS 上的硬盘都是久经沙场的拆机盘,同时,为了最大化的利用磁盘空间,没有对其做类似 RAID 1 或是 RAID 5,就是这两个点让这次磁盘空间损毁的事故成为必然。
机器内的四块拆机盘属这块希捷 500G 通电时间最短,健康检查来看也是相对较好的,所以我将其作为了群晖的第一块盘,单独划作存储池并作为我的主要存储空间,存储一些相对重要的文件。其他的几块通电时间长,甚至有一两个坏道的硬盘作为 PT 下载等其他一些临时资源的存储。可惜真应了那句话,硬盘坏不坏跟通电时间没有必然关系,由于那阵子家里那边变压器检修频繁停电,导致群晖在运行的时候异常断电了三次,在断电第三次的时候,好死不死的挂掉了这块希捷 500G 的套件盘。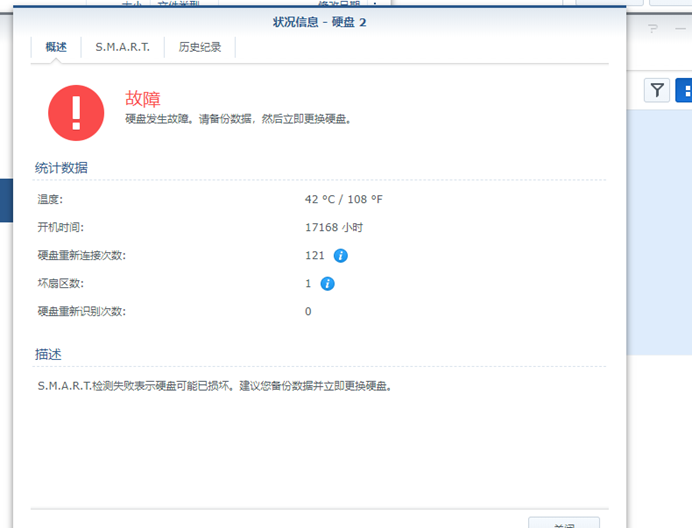
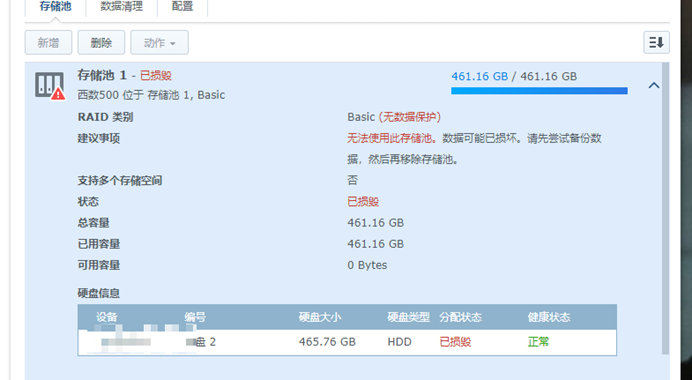
事故分析
第一块套件所在的存储空间损毁,意味着群晖上除去必要组件(即新装系统自带的那几个组件)能够使用外,其他所有的套件都无法使用,甚至存储空间都无法挂载。针对这类事故处理的最好的结果当是所有套件恢复正常使用,存储空间的所有文件正常读写,所以,我后面的所有都是围绕着这个结果去做的。
首先我们来说说,群晖为什么会有存储空间损毁这种机制,而且明明硬盘才那么几个坏道就报损毁了,拔出来格式化插到 Windows 下又能正常使用。
群晖的存储池的实现其实就是 Linux 下的软 RAID,我们通过 ssh 连接群晖并获取 root 权限 后,执行 cat /proc/mdstat 便可通过类似如下输出看到当前系统的软 RAID 信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19root@Alliot-blog # cat /proc/mdstat
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4]
md4 : active raid1 sdf3[0]
112398784 blocks super 1.2 [1/1] [U]
md3 : active raid1 sda3[0]
307749184 blocks super 1.2 [1/1] [U]
md2 : active raid1 sde5[0] sdb5[1]
483563456 blocks super 1.2 [1/1] [UU]
md1 : active raid1 sda2[0] sdb2[5] sdc2[1] sdd2[2] sde2[3] sdf2[4]
2097088 blocks [16/6] [UUUUUU__________]
md0 : active raid1 sda1[0] sdb1[5] sdc1[1] sdd1[2] sde1[3] sdf1[4]
2490176 blocks [16/6] [UUUUUU__________]
unused devices: <none>
大致从 blocks 大小结合实际硬盘容量看一下,md1 与 md2 估计为引导盘。从 md2 开始才是我们创建的存储池。
利用 mdadm 命令可以查看相应的存储池(阵列)详细信息:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25root@Alliot-blog # mdadm -D /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Sun Jan 26 16:50:01 2020
Raid Level : raid1
Array Size : 483563456 (461.16 GiB 495.17 GB)
Used Dev Size : 483563456 (461.16 GiB 495.17 GB)
Raid Devices : 1
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Mon Aug 24 16:08:07 2020
State : clean, FAILED
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Name : Alliot-blog:2 (local to host Alliot-blog)
UUID : 88a869b3:91601c6b:f79ab51d:eee415ed
Events : 261
Number Major Minor RaidDevice State
0 8 19 0 faulty active sync /dev/sdb3
通过 state 字段了解到当前的这个存储池的状态是不正常的。
当然,这里得可以看到我们的硬盘的设备文件为 /dev/sdb,也可以使用 smartctl -a /dev/sdb 来查看硬盘的 “S.M.A.R.T” 信息,获取硬盘健康状态指标。
再来看看为什么当前的存储空间无法进行写入等操作(甚至在 File Station 里都无法看到有相应的共享文件夹)1
2root@Alliot-blog # mount |grep volume1
/dev/md2 on /volume1 type btrfs (ro,relatime,synoacl,space_cache=v2,auto_reclaim_space,metadata_ratio=50,subvolid=257,subvol=/@syno)
可以看到, /volume1 当前是以 ro(即 read only) 模式挂载的,当然无法进行任何写入与修改的操作。(那些无法看到共享文件夹的,估计这里直接是取消挂载了)。
到这里为止,大概能够猜测群晖是通过判断软 RAID 的健康状态来决定是否将存储空间标记为损毁的了。有了这些信息我们能够大致知道怎样去抢救数据了。
事故处理
看到这里其实很多朋友都会说了,既然是 ro 模式了,我们直接对它 remount 到 rw 不就行了?又省一块盘?嗯… 这个作为一个正常人肯定都会这么去想,但是当你对它去进行 mount remount,rw 时,会发现并不能如我们所愿重新挂载,多次 remount 再去看挂载模式依旧是只读,而且还没有相关的报错信息。这里我猜测大概率群晖有一定的策略限制(或许是一个循环逻辑?)以保护坏盘中的数据不被进一步破坏。到这里省一块盘的想法可以抛去了。当下只能搬出数据以挽回部分损失了(虽然我有对文件添加一定的备份策略,但是套件数据及配置还是很重要的)。
群晖的 File Station 中无法进行操作,所以我们需要做的是将这个存储空间里的文件通过命令行拷贝到我们其他的硬盘上:1
2
3
4
5将块设备mount到一个挂载点(如果mount |grep volume1可以看到有挂载只不过是ro,那么跳过这一步,切记!) 这里我们前面查到的我们要的是md2所以直接执行:
mount /dev/md2 /volume1
cd /volume1
ll # 列出来的开头为 @ 的即为部分套件数据,按需进行备份转移
这里稍微啰嗦一下,由于硬盘必定是存在问题的(大多数为物理坏道),我们在转移备份数据的时候,因当按照数据的重要程度进行转移,因为在有物理坏道的情况下读取数据,很容易雪崩导致坏道暴涨,直接导致数据无法读取。
事故反思
回顾这次的磁盘空间损毁,由于自己一直都有备份的习惯,加上本身也没有存放太多有用的数据,所以主要的折腾点还是在于部分套件的设置丢失(直接恢复的套件还是有一些奇奇怪怪的问题,所以我索性重装了 DSM)。
备份
关于备份,我推荐的做法是参照企业做法,将数据按照等级来分类,当然,我们的数据不需要分的那么细。Alliot 将自己的数据简单分为如下三类: 重要数据信息、内部数据信息、普通数据信息。
重要数据信息 主要为:涉及个人自身与家庭成员信息的(如家人朋友珍贵或是隐私的照片与视频、书信扫描、证件凭证扫描、登陆凭证信息等),这类信息往往是丢失即没有机会再得到的,或是泄露会带来很多麻烦甚至影响生活的,所以,在安全与隐私方面都需要进行严格的把握。因此,我推荐的做法是机械硬盘等介质,三份以上的归档存储并放置于不同的地方,所有数据按照自己的规则进行打包加密,开启类似 Bitlocker 等加密手段,并且密码应当有一定的复杂度,且熟记。定期维护与检查。这类数据通常数量不多,因此其实成本也不会太高,Alliot 到现在也还没有装满 500G。不是很推荐直接存云存储(尤其是国内)。较为推荐的是分卷压缩并加密,分卷存放于不同的云盘进行二次加密以容灾。特别注意:这类数据不建议直接存放于 NAS 等联网的设备中,尤其是自己没有良好的安全意识与一定的专业知识的情况下。
内部数据信息 主要为: 工作记录、代码与学习笔记、普通日常照片视频以及通讯录备份等,这类信息隐私程度不至于像 “重要数据信息” 那样敏感与不可再生,通常会频繁使用与更新,经常于家人朋友间内部传播流通,因此不适合像重要数据信息那样进行归档存储。这类信息我一般选择存放于自己的 NAS 中,配以较高的密码复杂度,软件配置一定的周期,定期进行多盘备份以及加密同步到国外云盘,并开启版本控制,不定期进行移动硬盘冷备。群晖 Drive + Cloudsync + HyperBackup + RAID 1 基本满足软件层面的需求。
普通数据信息 则主要为一些高清电影、大姐姐视频(啊 不 没这回事)、 收藏的软件安装包等重要程度较低的文件,这些文件花一点时间通常可以再下载回来。因此,我通常是 Basic 存储空间配以 HyperBackup 套件备份到淘汰的盘里,同时搭配 Cloudsync 备份到云盘。
NAS存储策略推荐
由于群晖系统的特性,为了减少倒腾系统与数据的风险,强烈推荐第一个存储空间使用 RAID 1 模式,并使用全新的硬盘(Alliot 是用的狗东自营 4T 紫盘 *2 )。关于硬盘这里插一句: 紫盘完全是可以的,有人说监控盘忽略 CRC 错误会导致数据损坏,不适合做文件类存储,其实是不正确的,监控盘的忽略 CRC 错误的指令需要监控主机去主动开启,正常 PC 或 NAS 使用与其他盘没有区别。加上本身监控盘转速慢,也经常是 7*24 的环境,所以在我看来,给 NAS 使用没有一点问题(转速的原因,读写速度会比企业盘慢),不过钱包够的话,还是推荐企业级。
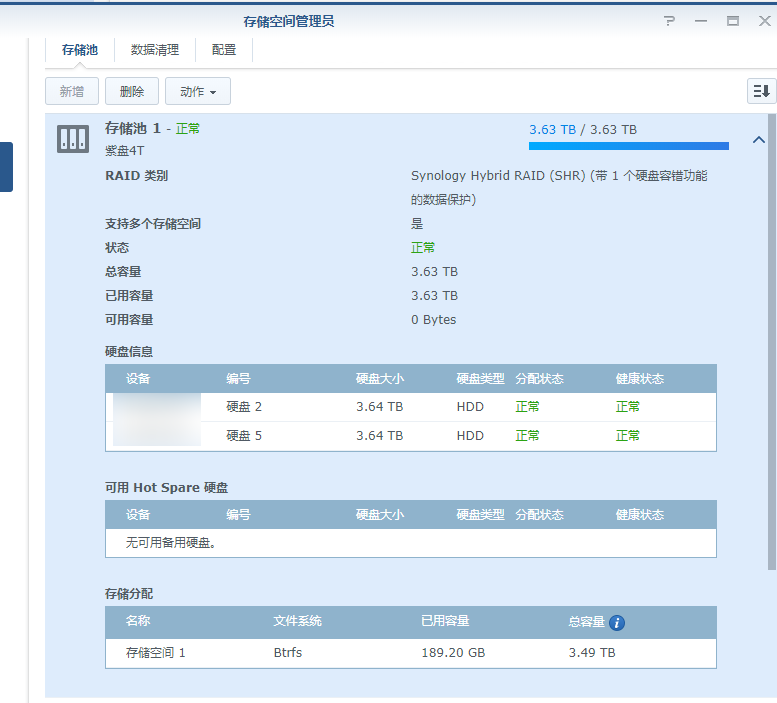
除去第一个存储空间外,其他的存储空间推荐 Basic 模式,并使用 HyperBackup 按照文件夹互相备份需要备份的内容,这样配置更加灵活,在一定程度上保证数据安全的同事,大大的节省了存储空间。
文件系统第一个存储空间还是推荐使用 Btrfs 格式,由于 Btrfs 文件系统本身的一些特性,群晖在这种类型下能够做更多的事情。(部分套件要求 Btrfs)
其他数据盘可以使用 ext4 或其他文件系统格式,但推荐程度一般。许多网友说的是方便在 Linux 下挂载并数据恢复等。但其实 Btrfs 在诸如 RedHat 等 Linux 发行版下都是原生支持 Btrfs 的,使用 mount -t btrfs 设备名 挂载点 是能够直接挂载的。 这个还是看个人喜好吧,区别不大。
结语
其实 Alliot 早已经将蜗牛星际退休,攒成了六盘位的 ITX 黑群晖了,并且配上了 APC UPS,后面有空的话也会分享一下攒机的记录。互联网公司确实会忙很多,前面也在考证,所以这篇博客兜兜转转,直到今天才完成,文中可能也能感觉到明显的行文断层,见谅。群晖系列的下一篇会是网络安全方面的一些闲聊,谈谈对于群晖(或不仅仅是群晖)的一些基本的安全加固。