浅谈微服务k8s情景下的日志采集
传统虚拟机、物理机环境下,日志文件通常存放于固定的路径下,当应用重启或出现异常退出的情况,日志也会留存下来,不受影响。而 Kubernetes 环境下,提供了相比前者更为细粒度的资源调度,容器(或 Pod)的生命周期是十分短暂的,当主进程退出,容器(或 Pod)便会被销毁,随之而来的是其关联资源也会被释放。因此,在日志采集的这个点上,Kubernetes 场景相比传统环境而言,会更为复杂,需要考虑的点更多。
普遍来说,Kubernetes 环境下的日志采集有如下几种模式:
| DockerEngine | 业务直写 | DaemonSet | Sidecar | |
|---|---|---|---|---|
| 采集日志类型 | 标准输出 | 业务日志 | 标准输出+部分文件 | 文件 |
| 部署运维难度 | 低 | 低 | 一般,维护daemonSet即可 | 高,每个需采集日志的Pod均需部署Sidecar容器 |
| 隔离程度 | 弱 | 弱 | 一般,只能通过配置间隔离 | 强,通过容器隔离,单独分配资源 |
| 适用场景 | 测试环境 | 对性能要求极高的业务 | 日志分类明确、功能较单一的集群 | 大型集群、PaaS型集群 |
- DockerEngine 直写一般不推荐,也很少会用到;
- 业务直写推荐在日志量极大的场景中使用;
- DaemonSet 一般在节点不超过1000的中小型集群中使用;
- Sidecar 推荐在超大型的集群或是日志需求比较复杂的情况中使用。
因为我司有日志处理分析等需求,所以同时应用了 DaemonSet 与 Sidecar 两种模式。业务直写方案也有少部分复杂场景会用到,因此,本文主要介绍前面两种日志采集模式。
DaemonSet 模式采集日志
由于我们不会在 Kubernetes 下直接运行容器(Kubernetes 的最小资源调度管理单位为 Pod),Kubernetes 会将日志软链至 /var/log/pods/ 与 /var/log/containers 路径下,以帮助我们更好的管理日志。
我们登陆任意一个 k8s 节点:1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@ali-k8s-test-002 ~]# cd /var/log/pods/
[root@ali-k8s-test-002 pods]# ls
comp-tools_skywalking-oap-ff949d984-kqnkx_51faece4-3b59-429d-99bf-a8fea9726555
comp-tools_skywalking-ui-95bd55c59-5x2qf_1422b8bd-988a-4739-bc96-53ccd9e164e6
kubesphere-controls-system_kubectl-zhangminghao-6c654bc9c8-m46sj_5eae93cb-fbf4-46a6-ba5c-c728ccb73d1b
kubesphere-devops-system_ks-jenkins-645b997d5f-tvlrs_a0d2ab73-d440-4d85-aa7c-612c3415341e
kubesphere-logging-system_elasticsearch-logging-data-1_6baa822d-f877-4f5f-ba5f-3e0e98a7d617
kubesphere-logging-system_elasticsearch-logging-discovery-0_0611bdb7-1989-4a06-a333-06ff045a4b1d
[root@ali-k8s-test-002 pods]# cd /var/log/containers
[root@ali-k8s-test-002 containers]# ll
总用量 180
lrwxrwxrwx 1 root root 136 4月 12 2021 ack-node-problem-detector-daemonset-vb4wm_kube-system_ack-node-problem-detector-3a8538726f9943d78e81395f29a4c39f3a831042b6264b34bc76068810272b78.log -> /var/log/pods/kube-system_ack-node-problem-detector-daemonset-vb4wm_3d088618-4af7-4def-913a-b85a74b06911/ack-node-problem-detector/0.log
lrwxrwxrwx 1 root root 136 5月 11 2021 ack-node-problem-detector-daemonset-vb4wm_kube-system_ack-node-problem-detector-6b6d7ef089f0fc352afcf3f04aa2a189e92483580e4797fab9298ed7e7eae43f.log -> /var/log/pods/kube-system_ack-node-problem-detector-daemonset-vb4wm_3d088618-4af7-4def-913a-b85a74b06911/ack-node-problem-detector/1.log
可以大致的看出其命名结构为: /var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/,/var/log/containers/<pod_name>_<namespace>_<container_id>。(扩展阅读: Where are Kubernetes’ pods logfiles? – StackOverflow )
因此我们只需要在每个节点上都部署采集器,通过 filebeat 等采集器对该路径下的日志进行采集即可。
那么,我们如何方便做到在 k8s 的每个节点上都部署一个采集器呢?这时候我们需要用到 k8s 中 daemonSet 这样的一种资源类型:
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。 daemonSet | Kubernetes
架构示意如下: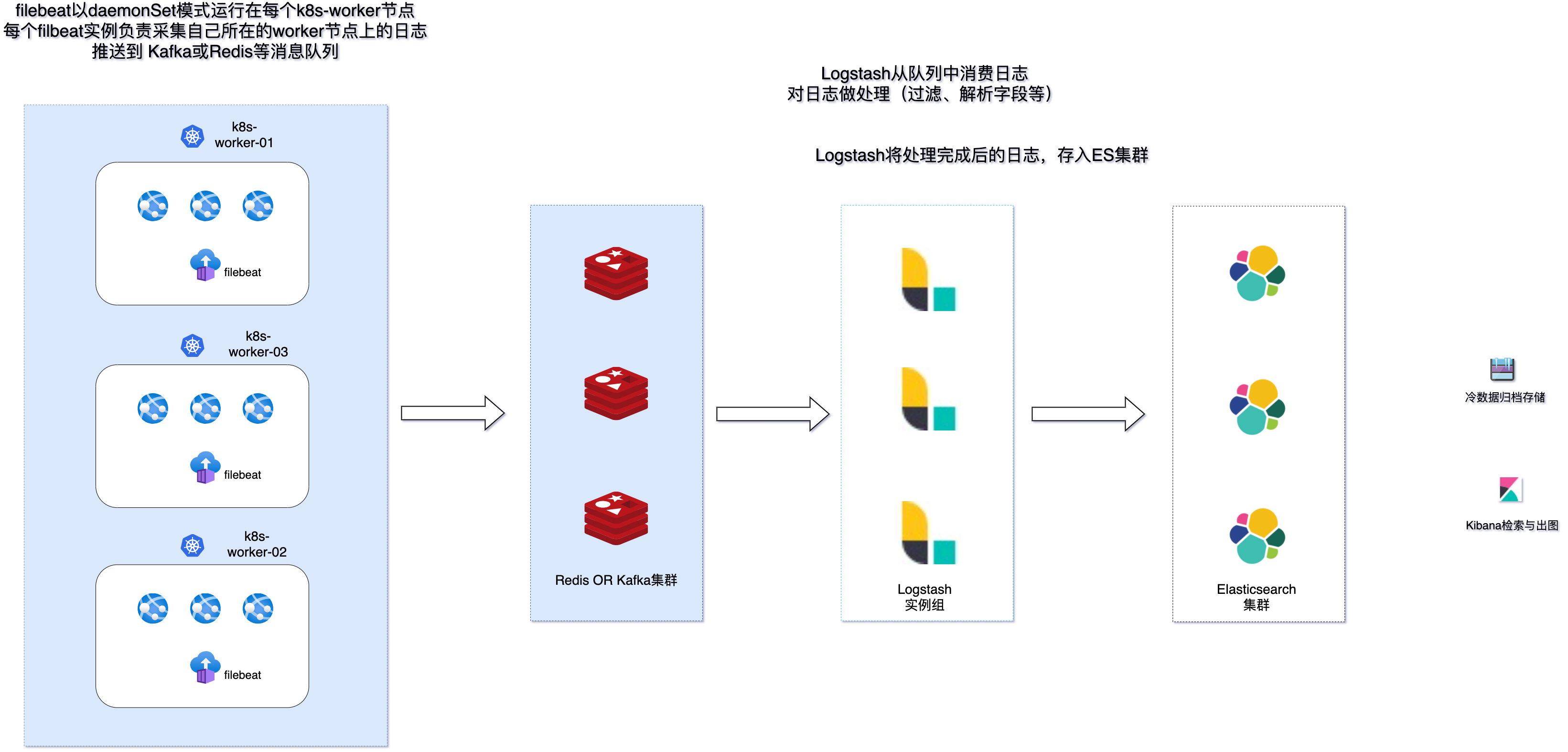
值得注意的是,这种模式下,需要统一应用的日志输出模式为标准输出错误输出,这样才会被日志引擎正确捕捉写入日志文件。同时,目前主流的云服务提供商的 serverless 虚拟 k8s 节点均不支持 daemonSet 模式,有此应用场景的需要使用其他方式来采集日志。
我们大概看一下这种模式的 filebeat 部署文件与配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: filebeat
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
hostAliases:
- ip: "192.168.201.126"
hostnames:
- "kafka01"
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.14.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
resources:
limits:
memory: 800Mi
requests:
cpu: 400m
memory: 200Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlog
mountPath: /var/log
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: dockersock
mountPath: /var/run/docker.sock
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: dockersock
hostPath:
path: /var/run/docker.sock
- name: varlog
hostPath:
path: /var/log
- name: data
hostPath:
# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).
path: /var/lib/filebeat-data
type: DirectoryOrCreate
# 权限配置
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat
apiGroup: rbac.authorization.k8s.io
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: Role
name: filebeat-kubeadm-config
apiGroup: rbac.authorization.k8s.io
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
- apiGroups: ["apps"]
resources:
- replicasets
verbs: ["get", "list", "watch"]
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat
# should be the namespace where filebeat is running
namespace: kube-system
labels:
app: filebeat
rules:
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs: ["get", "create", "update"]
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: filebeat-kubeadm-config
namespace: kube-system
labels:
app: filebeat
rules:
- apiGroups: [""]
resources:
- configmaps
resourceNames:
- kubeadm-config
verbs: ["get"]
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
app: filebeat
filebeat 配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
apiVersion: v1
kind: ConfigMap
metadata:
namespace: kube-system
name: filebeat-config
labels:
app: filebeat
data:
filebeat.yml: |-
filebeat.autodiscover:
providers:
- type: kubernetes
node: ${NODE_NAME}
templates:
- condition:
equals:
kubernetes.labels.filebeat_harvest: "true"
config:
- type: container
encoding: utf-8
paths:
- /var/log/containers/*${data.kubernetes.container.id}.log
# exclude_lines: ["^\\s+[\\-`('.|_]"]
# multiline:
# max_lines: 10000
# pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
# negate: true
# match: after
# symlinks: true
# 过滤边车模式的filebeat日志
processors:
- drop_event.when:
contains:
- kubernetes.container.name: "filebeat"
processors:
- drop_fields:
fields:
- "@metadata"
- "beat"
- "kubernetes.labels"
- "kubernetes.container"
- "kubernetes.annotations"
- "host"
- "prospector"
- "input"
- "offset"
- "stream"
- "source"
- "agent.ephemeral_id"
- "agent.hostname"
- "agent.id"
- "agent.name"
- "agent.type"
- "agent.version"
- "host.name"
- "input.type"
- "ecs.version"
- "input.type"
- "log.offset"
- "log.flags"
- "log.file.path"
- "version"
output.elasticsearch:
hosts: ["http://172.18.145.131:9200"]
enabled: true
worker: 1
compression_level: 3
indices:
- index: "%{[kubernetes.labels.filebeat_index]}-%{+yyyy.MM.dd}"
setup.ilm.enabled: false
setup.template.name: "ms"
setup.template.pattern: "ms-*"
setup.template.settings:
index.number_of_shards: 1
index.number_of_replicas: 0
查看 filebeat 实例在集群中的分布,可以看到每个 k8s 节点上都运行了一个 filebeat Pod:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16kubectl get pod -A -o wide|grep filebeat
kube-system filebeat-247nn 1/1 Running 0 24d 172.18.147.6 cn-shenzhen.172.18.147.6 <none> <none>
kube-system filebeat-2bvnm 1/1 Running 0 24d 172.18.146.224 cn-shenzhen.172.18.146.224 <none> <none>
kube-system filebeat-44b2q 1/1 Running 0 24d 172.18.146.200 cn-shenzhen.172.18.146.200 <none> <none>
kube-system filebeat-dh247 1/1 Running 0 24d 172.18.147.14 cn-shenzhen.172.18.147.14 <none> <none>
kube-system filebeat-qvrlk 1/1 Running 0 24d 172.18.146.201 cn-shenzhen.172.18.146.201 <none> <none>
kube-system filebeat-r4xmw 1/1 Running 0 24d 172.18.146.223 cn-shenzhen.172.18.146.223 <none> <none>
kubectl get node
NAME STATUS ROLES AGE VERSION
cn-shenzhen.172.18.146.200 Ready <none> 229d v1.18.8-aliyun.1
cn-shenzhen.172.18.146.201 Ready <none> 229d v1.18.8-aliyun.1
cn-shenzhen.172.18.146.223 Ready worker 238d v1.18.8-aliyun.1
cn-shenzhen.172.18.146.224 Ready <none> 238d v1.18.8-aliyun.1
cn-shenzhen.172.18.147.14 Ready <none> 174d v1.18.8-aliyun.1
cn-shenzhen.172.18.147.6 Ready <none> 209d v1.18.8-aliyun.1
sidecar 模式采集日志
先来了解一下什么是 sidecar:
Sidecar 即边车,类似港台警匪片里警察的三轮摩托车旁边的跨斗,它们都属于这台三轮摩托车,跨斗即为边车,充当辅助作用。
Pod 被作为 k8s 里管理的最小单元,一个 Pod 里可以包含一个或多个容器(container)。简单来说,如果把一个 Pod 类比成一台虚拟机,那么多个容器就是这个虚拟机里边的多个进程。
既然我们将 Pod 类比为了传统的虚拟机,那么我们的日志也就可以应用传统虚拟机上采集日志的模式: 每台虚拟机运行一个 filebeat 实例,采集指定路径下的日志文件即可。
转换过来就是: 每个业务Pod里除去应用容器,旁边还会跑一个filebeat等采集器的容器,应用容器通过共享存储的方式将日志文件挂载出来,filebeat 挂载这个共享存储来采集日志。
这样最大的好处就是,日志采集与处理的规则相比 daemonSet 要灵活,并且如果是从传统服务迁移到 K8S 里的应用,也可以延用先前的配置。
架构示意如下: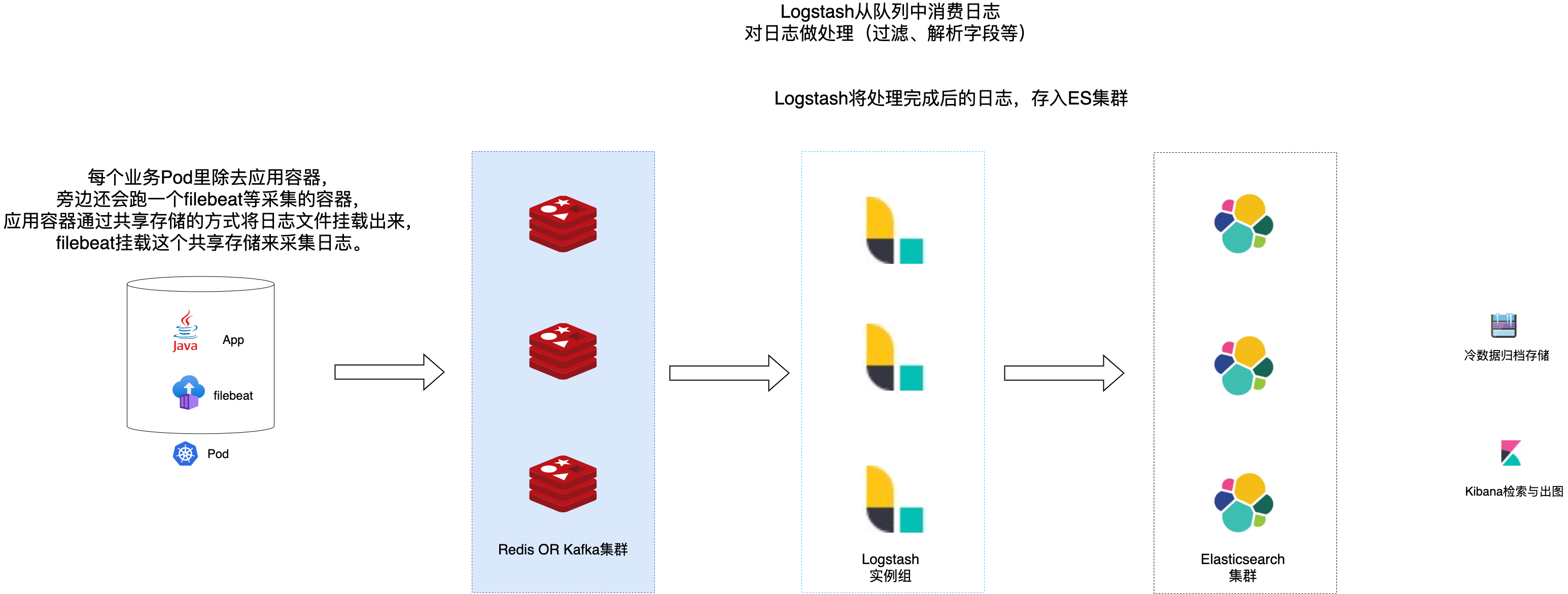
我们也大概看一下这种模式的 filebeat 部署文件与配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71apiVersion: apps/v1
kind: Deployment
metadata:
labels:
tier: backend
name: chat-api
namespace: default
spec:
replicas: 1
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
hostAliases:
- ip: "192.168.201.1"
hostnames:
- "kafka01"
nodeSelector:
common: prod
containers:
- name: chat-api
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
resources:
limits:
cpu: 1000m
memory: 1024Mi
requests:
cpu: 1000m
memory: 1024Mi
volumeMounts:
- name: service-logs-nas
mountPath: /data/logs/chat
- name: filebeat
image: filebeat:6.4.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 10m
memory: 30Mi
limits:
memory: 500Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: service-logs-nas
mountPath: /data/logs/chat
volumes:
# 这里因为有归档需求,所以通过NFS来共享存储
# 如果没有归档需求,可以直接使用 emptyDir 来共享存储
- name: service-logs-nas
nfs:
path: /prod-api
server: xxxx.cn-shenzhen.nas.aliyuncs.com
- name: filebeat-config
configMap:
name: filebeat-sidecar-chat-config
dnsPolicy: ClusterFirst
restartPolicy: Always
filebeat 配置如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-sidecar-chat-config
namespace: default
data:
filebeat.yml: |-
name: k8s-chat
filebeat.shutdown_timeout: 3s
filebeat.prospectors:
- input_type: log
paths:
- /data/logs/chat/*${HOSTNAME}*.log
json.keys_under_root: true
json.add_error_key: true
ignore_older: 12h
close_removed: true
clean_removed: true
close_inactive: 2h
fields:
k8s_nodename: ${NODE_NAME}
k8s_namespace: ${POD_OWN_NAMESPACE}
type: k8s-chat
format: json
output.kafka:
hosts: ["kafka01:20001]
topic: '%{[fields.type]}'
partition.round_robin:
reachable_only: true
username: "xxx"
password: "xxx"
required_acks: 1
compression: gzip
max_message_bytes: 1000000
worker: 1
这里我们再看看我们的 filebeat 实例在 k8s 中的存在形式:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86kubectl describe pod chat-api-74fb6c5c4c-zfs78
Name: chat-api-74fb6c5c4c-zfs78
Namespace: default
Priority: 0
Node: ali-hn-k8s05012-chat-prod/172.18.205.12
Start Time: Thu, 02 Dec 2021 23:04:31 +0800
Labels: tier=backend
Status: Running
IP: 172.18.128.168
IPs:
IP: 172.18.128.168
Controlled By: ReplicaSet/chat-api-74fb6c5c4c
Containers:
chat-socket:
Container ID: docker://e8ede98cc8c06040797378bf0563fe39949d2563b13e712d171f64abcfaebd02
Image: xxxx
Image ID: xxxx
Port: 8002/TCP
Host Port: 0/TCP
State: Running
Started: Thu, 02 Dec 2021 23:04:45 +0800
Ready: True
Restart Count: 0
Limits:
cpu: 1
memory: 2Gi
Requests:
cpu: 1
memory: 2Gi
Liveness: tcp-socket :8002 delay=5s timeout=1s period=2s #success=1 #failure=5
Readiness: tcp-socket :8002 delay=5s timeout=1s period=2s #success=1 #failure=5
Environment:
CACHE_IGNORE: js|html
CACHE_PUBLIC_EXPIRATION: 3d
ENV: test
SERVICE_PROD: $PORT
SERVICE_TIMEOUT: 120
POD_OWN_IP_ADDRESS: (v1:status.podIP)
POD_OWN_NAME: chat-api-74fb6c5c4c-zfs78 (v1:metadata.name)
POD_OWN_NAMESPACE: default (v1:metadata.namespace)
SERVICE_BRANCH_NAME: master
NODE_SERVER_TYPE: appForSocket
Mounts:
/data/logs/chat from service-logs-nas (rw)
filebeat:
Container ID: docker://b0df7f03590f09bc7eaf31fa931648c2b4bb652cff98abb8c8872cd11d8f7bea
Image: filebeat:6.3.2
Image ID: docker-pullable://docker.elastic.co/beats/filebeat@sha256:af6eb732fece856e010a2c40a68d76052b64409a5d19b114686db269af01436f
Port: <none>
Host Port: <none>
Args:
-c
/etc/filebeat.yml
State: Running
Started: Thu, 02 Dec 2021 23:04:45 +0800
Ready: True
Restart Count: 0
Limits:
memory: 500Mi
Requests:
cpu: 10m
memory: 30Mi
Environment:
NODE_NAME: (v1:spec.nodeName)
POD_OWN_NAMESPACE: default (v1:metadata.namespace)
Mounts:
/data/logs/chat from service-logs-nas (rw)
/etc/filebeat.yml from filebeat-config (rw,path="filebeat.yml")
/var/run/secrets/kubernetes.io/serviceaccount from default-token-95mrq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
service-logs-nas:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: xxxx.cn-shenzhen.nas.aliyuncs.com
Path: /prod-socket
ReadOnly: false
filebeat-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: filebeat-sidecar-chat-config
Optional: false
Events: <none>
可以看出这个 Pod 中存在两个 container,分别为业务应用 container 与 filebeat 实例。
应用直写模式采集日志
这种模式其实没啥特别需要讲的,一般是在业务应用的日志插件里直接推送日志,如 log4j 等日志引擎都能很方便的推送日志到 Kafka 等中间件或远程 Elasticsearch 中。
这种模式耦合度较高,适用于比较复杂或是对性能要求极高的场景下。
结语
很少有技术银弹能够一次性解决复杂生产环境中的所有需求,因此,日志采集也往往存在多种方案并存的情况,需要我们按照实际的需求来选择。