【转载】解决360网站安全检测的robots.txt漏洞
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。robots.txt的存在对SEO有一定的好处。
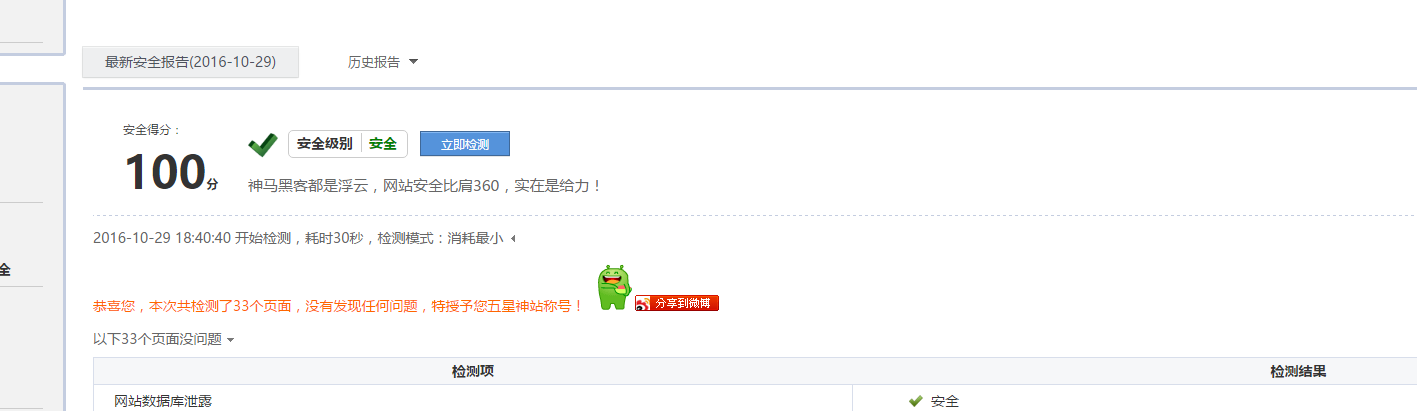
而360网站安全检测却提示“robots.txt文件有可能泄露系统中的敏感信息,如后台地址或者不愿意对外公开的地址等,恶意攻击者有可能利用这些信息实施进一步的攻击。”
转自@张戈博客
将robots只对搜索引擎开放,而其他访问均返回403就能够解决了,于是在nginx.conf中添加:1
2
3
4
5
6
7
8
9
10#若没有在UA中匹配到蜘蛛关键词(百度robots诊断为python检测,一并加上),那么设置 deny_robots变量为yes
if ($http_user_agent !~* "spider|bot|Python-urllib|pycurl") {
set $deny_robots 'yes';
}
#如果请求的是robots.txt,并且匹配到了蜘蛛,则返回403
location = /robots.txt {
if ($deny_robots = 'yes') {
return 403;
}
}
最后执行1
nginx -s reload
就行了。
先去站长平台看看robots.txt能不能抓取: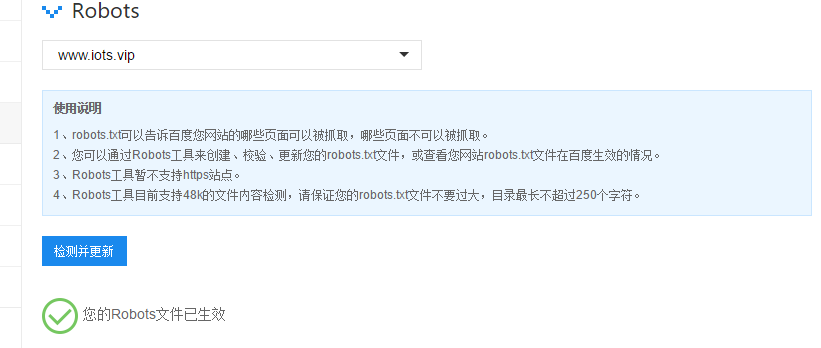
再访问一下/robots.txt:
最后再去360检测一下